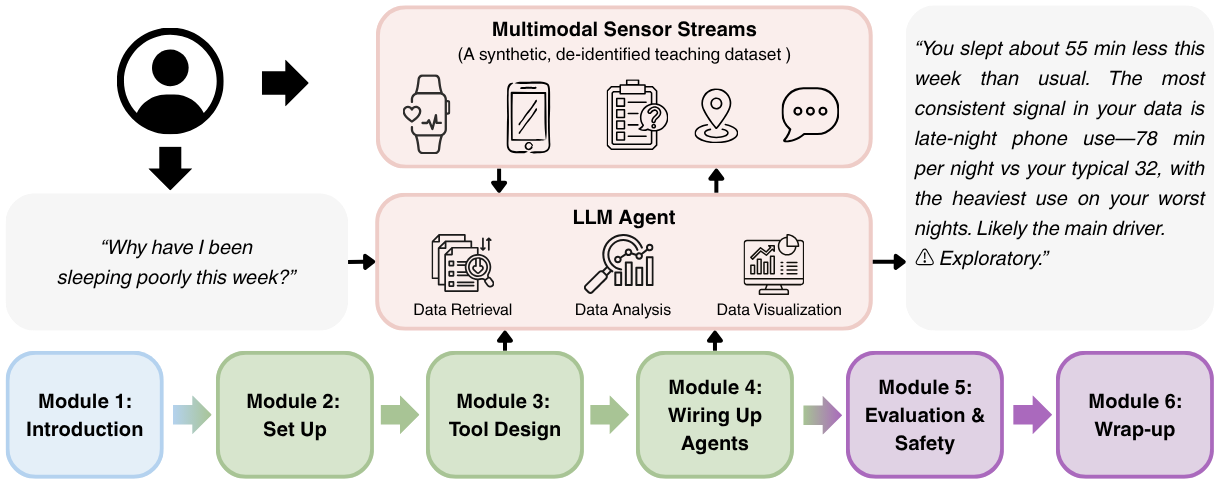
“Why have I been sleeping poorly this week?”
Most consumer wearables and health dashboards can show you the data behind that question, but they cannot answer it. LLM agents — language models that call functions, run analyses, and visualize results — offer a path to turn raw multimodal sensing streams into grounded, personalized answers. In this half-day, hands-on tutorial, you will build a working personal LLM health agent from a minimal scaffold, over a synthetic, curated multimodal sensing dataset (sleep, heart rate, activity, GPS, screen time, EMA).